RAG Explained: The Complete Guide to Retrieval-Augmented Generation for Enterprise AI (2026)
Somewhere in your organization right now, an AI assistant just answered a question with complete confidence and complete inaccuracy. It cited a policy from two years ago, a product that was discontinued last quarter, a procedure that was overhauled in the last report. The model wasn't broken. It was doing exactly what it was trained to do: recall patterns from data it absorbed during training, none of which includes your company's latest knowledge.
This is the hallucination problem. It costs enterprises more than credibility. It costs trust in an entire category of technology.
Retrieval-Augmented Generation (RAG) is the architecture built to fix it.
What Is RAG?
Retrieval-Augmented Generation (RAG) is an AI architecture that retrieves relevant documents from external knowledge sources and delivers them to a language model alongside the user's query, grounding every answer in real, current and verifiable information.
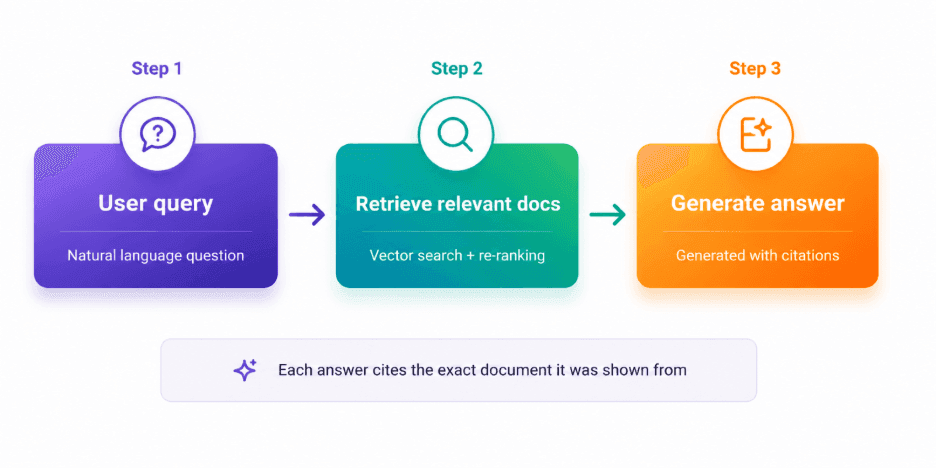
The clearest way to understand it: a standard large language model operates like a closed-book exam. The model draws only on what it memorized during training. RAG turns that into an open-book exam. When a user submits a question, the system first locates the most relevant pages in your knowledge base, then hands those pages to the model to read before generating a response.
The measurable outcome: hallucination rates fall by 75 to 90%. Organizations connect AI to proprietary data without retraining. Every answer traces back to a source document.
Here is how that three-stage process works in practice:
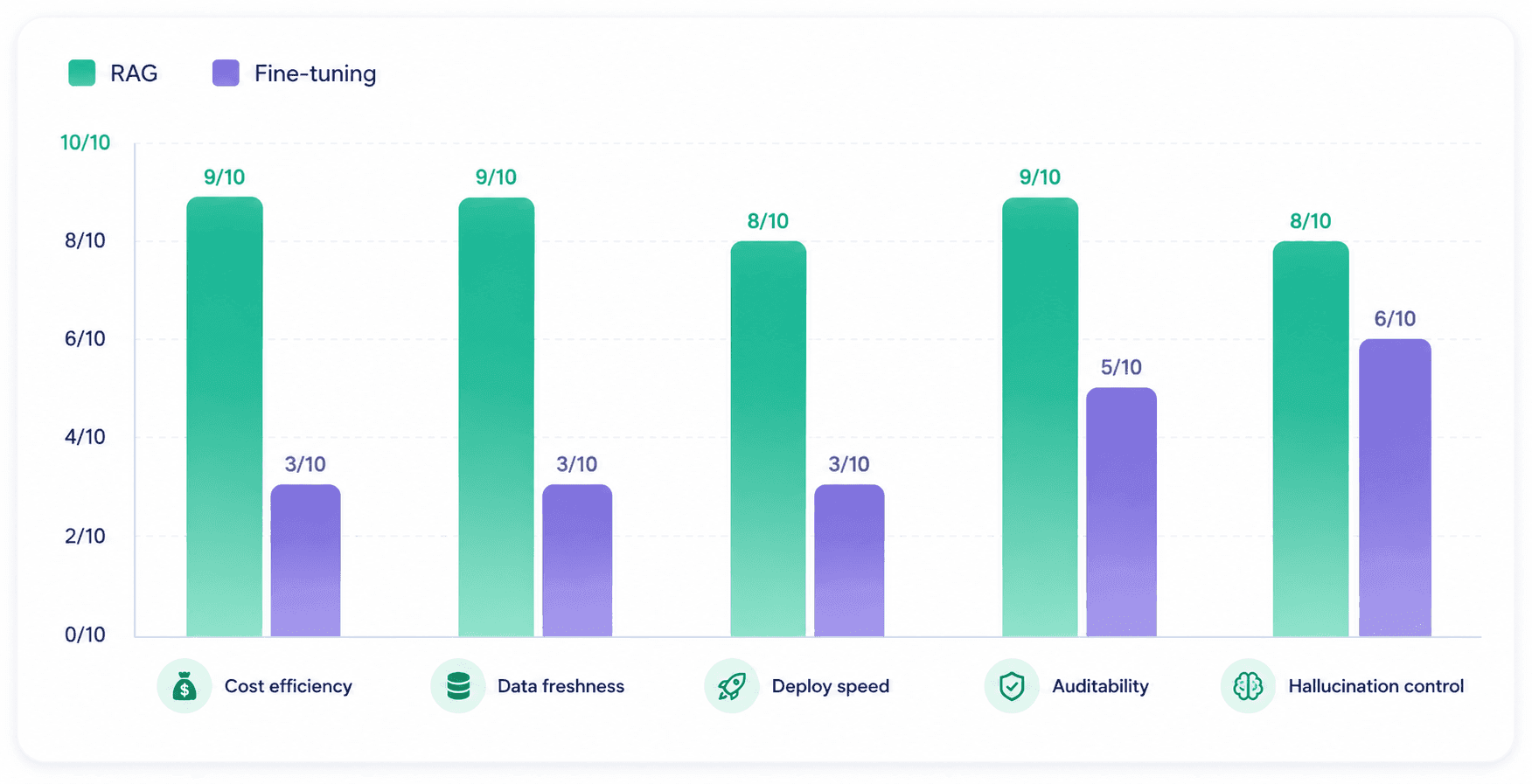
RAG vs Fine-Tuning
The most consequential decision teams face when adopting enterprise AI is whether to fine-tune a base model or build a RAG system. These are fundamentally different approaches with different cost profiles, deployment timelines and maintenance burdens.
Fine-tuning bakes knowledge into a model's weights through additional training. It is well suited for changing how a model reasons, behaves or writes, particularly in highly specialized domains like radiology or derivatives trading. The tradeoff is rigidity. Once a model is fine-tuned, updating its knowledge requires retraining. A regulatory update, a new product launch or a shift in company policy means going back to the training loop.
RAG connects the model to a live knowledge source at runtime. Updates to the knowledge base propagate immediately. Every answer can be traced back to a specific retrieved document, giving compliance and legal teams an audit trail that fine-tuning cannot provide.
The cost difference matters at scale. Fine-tuning a frontier model for an enterprise knowledge domain runs from $50,000 to several hundred thousand dollars. A well-architected RAG pipeline built on an existing model can be operational for a fraction of that, maintained with standard engineering tooling.
The question is rarely either/or. The most capable enterprise AI systems combine both approaches: RAG handles dynamic, auditable knowledge retrieval while fine-tuning shapes behavior, tone and domain-specific reasoning.
RAG Architecture Deep Dive
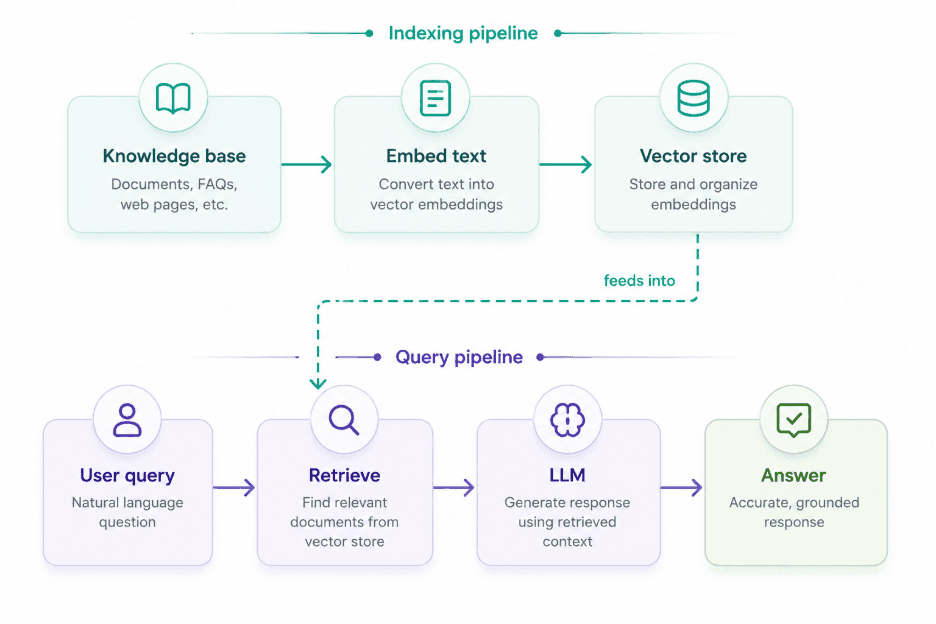
A production RAG system has five core components working in sequence.
Document ingestion is where everything starts. Raw content from PDFs, wikis, databases and APIs gets chunked into segments typically ranging from 256 to 1,024 tokens. Chunking strategy has an outsized impact on downstream quality. Chunks that are too small lose surrounding context. Chunks that are too large dilute retrieval precision.
Embedding follows. An embedding model converts each text chunk into a high-dimensional numerical vector. These vectors capture semantic meaning rather than exact keywords, which is what allows a search for "employee time off policy" to surface a document titled "PTO and leave of absence guidelines."
Vector storage gives those embeddings a home. Databases like Pinecone, Weaviate, Chroma and pgvector store millions of embeddings and support approximate nearest-neighbor search in milliseconds.
Retrieval is where the query enters. The user's question is embedded using the same model, then compared against stored vectors. The top-k most semantically similar chunks surface. Advanced pipelines add hybrid search (combining keyword and semantic signals) and re-ranking models to push the most useful chunks to the top.
Generation closes the loop. Retrieved chunks are inserted into the prompt alongside the user's question, and the LLM generates a response grounded in that specific content. Citations can be surfaced automatically, giving users direct links back to the source document.
Enterprise Use Cases
The gap between RAG's promise and its real-world value becomes clearest when you look at what organizations are actually shipping.
Internal knowledge assistants have become the highest-volume use case. A Fortune 500 insurer deployed RAG across its HR, IT and legal documentation, reducing time-to-answer for employee queries from 48 hours to under three minutes. The system handles over 12,000 queries per month with a hallucination rate below 2%.
Customer support is seeing comparable gains. A B2B software company connected RAG to its full product documentation library and saw support ticket deflection rise 34% in the first quarter. Every response includes a citation to the specific help article, which lets human agents verify and escalate with confidence.
Financial research and compliance teams use RAG to synthesize regulatory filings, earnings calls and internal research notes. The retrieval layer handles documents that change daily. The model handles synthesis and reasoning.
Healthcare has moved carefully but decisively. Clinical decision support tools built on RAG retrieve peer-reviewed literature and internal clinical guidelines at the point of care. The ability to cite sources is a regulatory requirement in this vertical, making RAG's auditability a structural competitive advantage.
Engineering and code documentation closes the list. Teams indexing their entire codebase, architecture decision records and runbooks into a RAG pipeline consistently report that new engineers onboard faster and senior engineers field fewer repetitive questions.
How to Implement RAG: A 6-Step Framework
Successful RAG implementations follow a consistent pattern across industries and team sizes.
Start with a knowledge base audit. Catalog your data sources, assess content quality and identify which material is high-value for your target use cases. Garbage in, garbage out applies with full force here, and no retrieval system rescues poor-quality source documents.
Choosing your embedding model and vector database is the next decision. OpenAI's text-embedding-3-large and Cohere's Embed v3 lead on benchmark performance for English-language enterprise content. Pinecone and Weaviate are the most operationally mature vector databases for enterprise deployments. pgvector is the natural choice if your stack is already PostgreSQL-centric.
Chunking strategy shapes retrieval quality more than most teams anticipate. Recursive character splitting is a safe starting point. Semantic chunking, which breaks at natural topic boundaries rather than fixed token counts, tends to improve precision for long-form documents like policies and contracts.
Build the retrieval pipeline progressively. Start with semantic search. Add hybrid search when keyword precision matters for your domain. Layer a re-ranking model when retrieval recall needs a second pass.
Integration with your LLM requires careful prompt engineering. The way retrieved context is presented to the model has a measurable impact on answer quality. Test multiple prompt structures before locking in a template.
Evaluation and monitoring must be ongoing. Three metrics matter most: faithfulness (does the answer follow from the retrieved content), relevance (are the retrieved chunks actually useful to the question) and latency (is the system fast enough for your use case). Tools like Ragas and LangSmith make all three measurable and trackable over time.
The Future of RAG
The architecture is evolving quickly, and the most significant shift is already underway.
Agentic RAG replaces a single retrieval step with a decision-making loop. Rather than retrieving once per query, agentic systems decide dynamically when retrieval is needed, which sources to query and whether to reformulate the search based on intermediate findings. This is how RAG moves from a question-answering tool to a genuine research capability.
Multimodal RAG extends retrieval beyond text to images, diagrams, charts and video frames. Enterprise knowledge is increasingly visual. Product manuals, engineering schematics and financial dashboards all contain information that text-only retrieval misses entirely.
Graph RAG combines knowledge graphs with vector retrieval. Where semantic search finds similar passages, graph traversal follows logical relationships between entities. The two approaches are complementary and tend to outperform either one alone on multi-hop reasoning tasks, where the answer requires connecting several distinct facts across different documents.
By 2027, RAG will be infrastructure rather than a feature. Every enterprise AI product will assume a live retrieval layer the same way every web application assumes a database. The organizations building that foundation today will not be playing catch-up when the baseline shifts beneath them.
Build Enterprise AI Systems with Reliable RAG Architecture
Accurate AI responses powered by real-time enterprise knowledge and intelligent retrieval.